SESIONES TEÓRICAS ESTADÍSTICA Y MÉTODO TIC: TEMA 8
TEORÍA DE MUESTRAS: Tipos de muestreo. Teoría de la estimación. Tamaño de la muestra.
ESTIMACIÓN E INFERENCIA ESTADÍSTICA
PROCESO DE LA INFERENCIA ESTADÍSTICA
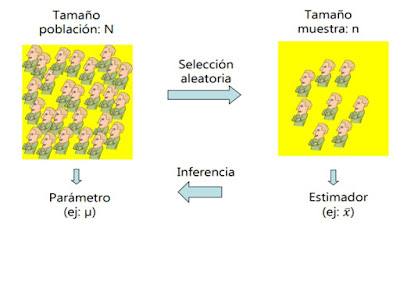
- Representativa de la población diana, que se evalúa mediante las técnicas de muestreos.
- De un tamaño adecuado. La muestra debe ser lo suficientemente grande para garantizar que se representa a la población diana y lo suficientemente pequeña para que se facilite su análisis. Este factor también influye en la representatividad.
- Comparable. En los estudios analíticos se comparan grupos y éstos deben ser similares al inicio del estudio, de esta manera, se podrá concluir que las diferencias encontradas entre ambos grupos serán o no consecuencia de la exposición o no al factor que se estudia o de la aplicación o no de la intervención.
PROCEDIMIENTO MUESTRAL
Tipos de muestreos

- Muestreo probabilístico, en él todas las unidades (los individuos) que componen la población tienen una probabilidad de ser elegid@s y se puede calcular de antemano.
- Muestreo no probabilístico, en él las unidades que componen la población tienen diferente probabilidad de ser elegidas ya que no solo interviene el azar sino también otras condiciones, concretamente, dependerá de la circunstancia. No se puede calcular la probabilidad de antemano y no todos los elementos tienen alguna posibilidad de ser incluidos, por ello, este tipo de muestreo tiene una representatividad dudosa.
MUESTREO NO PROBABILÍSTICO
Muestreo consecutivo
- El reclutamiento no se realiza de manera consecutiva, produciéndose interrupciones.
- El período de reclutamiento sea corto y no refleje fluctuaciones estacionales del problema que estamos estudiando.
Muestreo de conveniencia o accidental
Se recluta a los individuos que son más accesibles para el equipo investigador o que se presentan voluntariamente. Se usa con frecuencia al ser el menos costoso y mas fácil.
Desventajas:
Poco sólida ya que requiere de una gran homogeneidad de la variable estudiada en la población puesto que, de no ser así, se puede producir un sesgo al no recoger toda la heterogeneidad del fenómeno.
Ejemplo: Paramos por la calle a la gente que pasa por allí.
Muestreo intencional o a criterio
En esta técnica es el propio investigador es quien selecciona a los individuos al considerarlos los más apropiados. Se usa cuando se quiere contar con una muestra de expertos o en estudios cualitativos.
Desventaja:
Este método puede no contar con un método externo y objetivo para valorar la idoneidad de los sujetos.
Ejemplo: Si queremos saber qué dificultades encuentran los enfermeros para investigar usando una técnica de consenso, como la técnica Delphi, para seleccionar el grupo de expertos que participarán, podríamos optar por realizarlo mediante un muestreo a criterio, eligiendo a los sujetos que considerásemos más adecuados para formar la muestra.
Estos dos últimos tipos de muestreo no probabilístico (de conveniencia e intencional) son los que más se utilizan en la investigación cualitativa. Tenemos que tener en cuenta que la investigación cualitativa es útil debido a que no está respaldada completamente en los números y porque aporta un matiz que los números no dan.
Muestreo bola de nieve, de avalancha o muestreo en cadena
- La muestra puede ser reducida debido a la reducida red de contactos.
- Calidad de los participantes condicionada por la invitación de otros a confiar en el investigador.
Muestreo teórico
Se usa muy poco. La selección de la muestra se hace de forma gradual debido a que el propósito del estudio es la generación de una teoría o porque la integración de la muestra se va diciendo sobre la marcha con el fin de que los datos recogidos permitan capturar la máxima variación posible de significados.
Por tanto, los participantes deben cubrir todas la características, perfiles o patrones que pueden influir en los significados del fenómeno estudiado.
MUESTREO PROBABILÍSTICO
Muestreo aleatorio
Como su propio nombre indica, en la selección de los sujetos interviene el azar. Se distinguen dos tipos:
SIMPLE:consiste en seleccionar al azar (mediante una tabla de números aleatorios o el uso de un programa informático) un número n (tamaño muestral) de elementos de una población. Es el método más sencillo y, sin embargo, el menos utilizado, porque requiere contar a priori con un listado con todas las unidades que componen la población accesible, por lo que se utiliza cuando la población es pequeña. Es el método que produce muestras más representativas, ya que solo interviene el azar. y, sin embargo, no es muy utilizado por sus desventajas:
Es necesario contar con un listado enumerado de todas las unidades de población.
Los sujetos pueden estar muy dispersos por lo que contactar con todos ellos puede resultar costoso en tiempo y dinero.
Algunos subgrupos de población, especialmente los minoritarios, pueden no estar representados si la nuestra es pequeña.
SISTEMÁTICO: consiste en seleccionar individuos según una regla o proceso periódico. Para ello, seguiremos los siguientes pasos:
Calculamos la constante de muestreo "K", K = N/n , donde N es población candidata.
Elegimos un número al azar entre 1 y K, y esa será la primera unidad "r" de la muestra.
Sumamos la constante K al número r hasta conseguir el tamaño muestral, siendo el primer individuo quien ocupe la posición r, el segundo (r+K), el tercero (r+2K), el cuarto (r+3K)... y así sucesivamente.
Ventajas: no hace falta tener la lista completa.
Muestreo Estratificado
- Ventaja: conocer cómo se comporta una variable en cada subgrupo de la población con precisión.
- Desventaja: necesita más información y un listado de cada individuo de la población.
Muestreo Conglomerados
Es una técnica que aprovecha la existencia de grupos o conglomerados en la población que representan correctamente el total de la población en relación a la característica que queremos medir. Dicho de otro modo, estos grupos contienen toda la variabilidad de la población. Si esto sucede, podemos seleccionar únicamente algunos de estos conglomerados para conocer la información de interés del total de la población.
Podemos ver esta técnica desde otro punto de vista, mientras que en todas las técnicas vistas hasta ahora las unidades de muestreo coinciden con las unidades a estudiar (individuos), en el muestreo por conglomerados las unidades de muestreo son grupos de unidades a estudiar (grupos de individuos), algo que puede resultar muy beneficioso en términos de coste. A cambio, es habitual obtener una menor precisión al usar esta técnica, causada por falta de heterogeneidad dentro de los conglomerados. Para usar esta técnica de muestreo seguiremos los siguientes pasos:
Definir los conglomerados identificando una característica que permita dividir la población en grupos disjuntos (sin solapamiento) y de forma exhaustiva (todos los individuos deben estar en un grupo), de tal manera que los grupos no difieran entre sí en relación a aquello que queremos medir. Un criterio habitual para definir conglomerados es el geográfico.
Una vez hemos definido estos conglomerados, seleccionaremos al azar algunos de ellos para estudiarlos. mediante un muestreo aleatorio simple o sistemático.
Investigar a todos los sujetos que forman parte de los mismos, o bien aplicar un nuevo proceso de muestreo dentro del conglomerado, por ejemplo obteniendo una muestra mediante muestreo aleatorio simple o sistemático. Si optamos por esta posibilidad, estaremos hablando de un muestreo en dos etapas o bietápico: la primera etapa será la selección del conglomerado; y la segunda, la de individuos dentro del conglomerado. Si por el contrario estudiamos todos los individuos del conglomerado, hablaremos de muestreo por conglomerados unietápico.
Ventajas: es una técnica operativa, fácil de aplicar y económica.
Desventajas: no se conoce de antemano el tamaño de la muestra que se va a obtener ya que el tamaño depende de los grupos seleccionados y, además, si los conglomerados no son realmente homogéneos entre ellos se va a generar sesgo.
Tanto en el muestreo estratificado y por conglomerados dividimos la población en grupos. Sin embargo, los principios detrás de ambas técnicas son en cierto modo opuestos. El muestreo estratificado es especialmente adecuado cuando los grupos (estratos) son muy homogéneos internamente y muy diferentes entre sí. En ese caso, conviene asegurar que tenemos representantes en nuestra muestra que provienen de todos los estratos. Por el contrario, el muestreo por conglomerados es muy adecuado cuando los grupos en que dividimos la población son muy similares entre sí, por lo que no hay gran diferencia entre estudiar individuos de un grupo o de otro. Es por ello que pese a que ambas técnicas dividen la población en estratos o conglomerados, el proceso de selección de individuos es radicalmente diferente.
TAMAÑO DE LA MUESTRA
El cálculo del tamaño muestral, por su parte, permite determinar un número aproximado de sujetos que es necesario incluir en la muestra para que esta pueda ser representativa. Si no realizásemos este cálculo, podrían darse dos situaciones diferentes:
Que realicemos el estudio sin el número suficiente de pacientes lo que conlleva a que no podremos ser precisos al estimar los parámetros y además, que no encontremos diferencias significativas cuando en la realidad sí existen, es decir, que cometamos la que se llama error tipo II.
Que estudiemos a un número innecesario de pacientes, lo cual lleva implícito no solo la pérdida de tiempo sino también el incremento de recursos innecesarios. Además, si el muestreo no ha sido probabilístico, un tamaño muestral grande no tiene por qué garantizar que la muestra sea representativa, puesto que, como hemos visto, puede haber parte de la población que no esté representada en la muestra.
El tamaño de la muestra puede depender de los siguientes factores:
La variabilidad del parámetro que se quiere medir: cuán frecuente sea lo que deseamos medir. Si el fenómeno es muy frecuente, necesitaremos muestras más pequeñas que si se da con menor frecuencia. Para tener este dato (si el fenómeno es frecuente o no), debemos apoyarnos en los datos facilitados por otros estudios.
La precisión con la que queramos dar los datos, es decir, la amplitud del intervalo de confianza. Debemos pensar que cuanta mayor precisión queramos, más estrecho será el intervalo de confianza, o lo que es lo mismo, si ampliamos el intervalo de confianza con el que queremos dar los datos, el rango de valores también se amplía. El error estándar que se quiere asumir, en cualquier caso, es una decisión esencialmente subjetiva que, como ya hemos apuntado, depende del intervalo de confianza con el que los investigadores quieran trabajar a la hora de inferir los resultados.
El nivel de confianza, o lo que es lo mismo, la significación estadística del estudio: que en estudios de ciencias de la salud se establece, por acuerdo universal, como mínimo en un 95% o, lo que es lo mismo, (1 - α) = 0.95, y por tanto, un α = 0.05.
El poder estadístico o la potencia del estudio: está relacionado con la precisión del estudio, esto es, la capacidad que tiene el estudio para encontrar diferencias si es que realmente las hay. Por tanto, es un parámetro que se debe establecer en los estudios que pretenden probar hipótesis. El poder estadístico es el complementario de la probabilidad de cometer el error tipo II o β, por tanto, es igual a (1 - β).
El efecto esperado: en el caso de ensayos clínicos, debemos estimar a priori (a partir de la bibliografía existente) cuál será el efecto que esperamos obtener por la intervención realizada. En función de si el efecto es pequeño, mediano, o grande, el tamaño de la muestra deberá ser mayor o menor. Lógicamente, al igual que sucedía con la prevalencia o variabilidad del fenómeno, cuanto mayor sea el efecto esperado menor será el tamaño muestral, ya que tendremos más “garantía” o “probabilidad” de tener sujetos que lo presenten.
Para determinar el tamaño muestral de un estudio, debemos considerar los diferentes fines para los que se desarrolla un estudio:
- Estimar parámetros poblacionales: a partir de los datos obtenidos en la muestra que ha participado en el estudio (proporciones, medias) pretendemos hacer inferencias a valores poblacionales.
- Contrastar hipótesis: el estudio pretende comparar si existen diferencias en los valores medios o las proporciones de las variables a estudio entre los grupos que conforman la muestra.
Para el cálculo del tamaño de una muestra para estimar la media de una población tenemos una formula donde:
n= Z^2 x S^2 /e^2
Zα , es el coeficiente que corresponde al nivel de confianza prefijado.
– Para un nivel de confianza del 95%, α = 0.05, el valor de Zα = 1.96
– Para un nivel de confianza del 99%, α = 0.01, el valor de Zα = 2.57
S2, es la varianza de la distribución de la variable cuantitativa que se supone existe en la población. Este dato lo podemos obtener de estudios previos o de un estudio piloto.
e, es la precisión con la que se desea estimar el parámetro (también fijado por los investigadores) .
Por tanto, para calcular el tamaño muestral necesario para estimar una media necesitamos saber solo el valor de S2, puesto que tanto el valor de Zα como el de e es fijado por los investigadores.
Si no tuviéramos datos acerca del valor aproximado de la varianza, ni fuera posible realizar un piloto, podemos obtener una primera aproximación al valor de la varianza a partir de la estimación de la desviación típica, s, (que, como se ha explicado ya en un tema anterior, es la raíz cuadrada de la varianza), se podría utilizar una regla práctica que consiste en determinar la diferencia entre los valores máximos y mínimos esperables, y dividir esta diferencia entre 4. El número obtenido se aproxima al de la desviación típica, s.
Para calcular el tamaño de una muestra cuando queremos estimar una proporción:
n=N*Z^2*P(1-P)/(N-1)*e^2+Z^2*P(1-P)
Donde:
Zα , es el coeficiente que corresponde al nivel de confianza prefijado.
– Para un nivel de confianza del 95%, α = 0.05, el valor de Zα = 1.96
– Para un nivel de confianza del 99%, α = 0.01, el valor de Zα = 2.57
p, es el valor aproximado del parámetro que se quiere medir (su variabilidad o cuán frecuente es) expresado en términos de probabilidad, es decir, en tanto por uno. Este dato lo podemos obtener de estudios previos o de un estudio piloto.
(1 - p), es el complementario del valor de p.
e, es la precisión con la que se desea estimar el parámetro (también fijado por los investigadores).
Por tanto, para calcular el tamaño muestral necesario para estimar una proporción necesitamos saber solo el valor de p, puesto que tanto el valor de Zα como el de i es fijado por los investigadores, y el de (1 - p), se calcula a partir del valor de p.
Si no tuviéramos datos acerca del valor aproximado del parámetro que se está buscando, ni fuera posible realizar un piloto para obtener una primera aproximación a dicho valor, se puede adoptar la postura de máxima indeterminación y considerar que el parámetro estará presente en la mitad de los sujetos estudiados (lo mismo que se daría por azar), que es el valor que requiere mayor cantidad de individuos. Su inconveniente es que estudiaríamos a un número de sujetos superior al necesario para garantizar la representatividad de la muestra.



Comentarios
Publicar un comentario